Your comments
I think I did something wrong. I copied folder-info.html, folder.css, and publisher to the root of the comic's file system and this happens under google & chrome. Are there additional files needed
Great job! What tweak would need to be made to align the images to the top?
Looks great! Now if only comicvine had decent story arc data
To enhance volumes you would do ( Notice we send everything through the fifo and read everything once, and we didn't need to extend the logic much; we add the new elements we want )
query=description,date_last_updated,name,start_year,publisher
query2=name,start_year,publisher,date_last_updated
id=87604
curl -s "http://comicvine.gamespot.com/api/issues/?api_key="$apikey"&field_list=$query&format=xml&filter=issue_number:1,volume:"$id | xml2 > /tmp/comics.fifo &
curl -s "http://comicvine.gamespot.com/api/volume/4050-$id/?api_key="$apikey"&field_list=$query2,&format=xml "| xml2 > /tmp/comics.fifo &
{ while read gimme;
do
case $gimme in
/response/error*) status=${gimme##*=} ;;
/response/results/issue/name*) name=${gimme##*=} ;;
/response/results/name*) title=${gimme##*=} ;;
/response/results/issue/date_last_updated*) update_date=${gimme##*=} ;;
/response/results/issue/description*) description=${gimme##*=} ;;
/response/results/publisher/name*) publisher=${gimme##*=} ;;
esac
done } < /tmp/comics.fifo
case $status in
OK) echo date :$update_date
echo title :$title
echo name :$name
echo Publisher :$publisher
echo description: $description;;
*) echo "No results return for $id";;
esac
Scott how do you feel about adding delta detection to your code? I was thinking if you pulled the last update date from comic vine you could update folder-html and potentially the comic book ( If you check the ComicInfo.XML stored in the cbz for story arc ). Here were some quick scenarios I came up with that keeps folder-htlml, ubooquity and the files metadata in sync with comicvine
| Object | Description | Date Item was imported |
Description Last Updated | Last Update Date from Comic Vine | Data Storage | Action |
| Comic A | Adventure | 01/01/15 | Excitement | 02/15/15 | Folder-html | Pager Builder regenerates the folder-html |
| Comic A :File 1 | Yoda | 01/01/15 | Rey | 07/15/15 | File ComicInfo.XML / Ubooquity DB | Page Builder kick off comic tagger. |
| Comic A :File 2 | Vader | 01/01/15 | Vader | 01/01/15 | File ComicInfo.XML / Ubooquity DB | No action required since no change occurred |
| Comic B | Jedi | 01/01/15 | Sith | 06/01/15 | Folder-html | Pager Builder regenerates the folder-html |
| Comic A :File 2 | Daddy Issues | 01/01/15 | She my sister | 07/04/15 | File ComicInfo.XML / Ubooquity DB | Page Builder kick off comic tagger. |
| Story Arc | JarJar | 01/01/15 | Death of JarJar | 10/31/15 | Folder-html | Pager Builder regenerates the folder-html |
Protocode
- This would go in page builder and evolve the rawDesc logic
- preq sudo apt-get install xml2 this will make parsing a breeze
- using XML allows you to easly modify the case statement vs using nested if
- Notice you can add more fields to the gimmie logic by just adding the XML anchor and grabbing what's after =
#!/bin/bash
mkfifo /tmp/comics.fifo
apikey="<put your key here>"
query=description,date_last_updated,name,start_year
id=87604
curl -s "http://comicvine.gamespot.com/api/issues/?api_key="$apikey"&field_list=$query&format=xml&filter=issue_number:1,volume:"$id | xml2 > /tmp/comics.fifo &
{ while read gimme;
do
case $gimme in
/response/error*) status=${gimme##*=} ;;
/response/results/issue/name*) name=${gimme##*=} ;;
/response/results/issue/date_last_updated*) update_date=${gimme##*=} ;;
/response/results/issue/description*) description=${gimme##*=} ;;
esac
done } < /tmp/comics.fifo
case $status in
OK) echo date :$update_date
echo name :$name
echo description: $description;;
*) echo "No results return for $id";;
esac
Proto results
date :2016-01-26 12:32:48
name :Volume 2
description: <p><em>Calling all kidz! Do you like comics? Do you like laughing till milk comes out of your nose?! Look no further--do we have the book for you! All your favorite comic creators are right here in one book. This all-star tribute to classic Sunday comics includes eight sidesplitting, action-packed stories about every kid's favorite subject - lunch! A bust-your-gut laughing graphic novel anthology with original contributions from the most beloved names in the genre: Jennifer Holm & Matthew Holm, Jarrett J.Krosoczka, Sara Varon & Cecil Castellucci, Cece Bell, Jason Shiga, Nathan Hale, Jeffrey Brown, and the Peanuts.</em></p>
that is a good point or we could correct the source system 🍿🤔
I think any user can correct Comicvine. Comicvine may just be missing a way to perform bulk edits.
Though I'm thinking that reconciliation become a manual effort. Can you share your thoughts on how you envision the reconciliation process
Also side not almost every field has a update date. If Scott's code pulled the date it could automatically update the descriptions when a change occurs 🍿😊
These are just some of the fields we're not using http://comicvine.gamespot.com/api/documentation
Was tinkering around and here's how story arcs would look. DC had about 5 pages, so I'm wondering if you might need to group Story Arcs by publishers. In my code , I switched from symbolic links to hard links to get ub to pick up the files
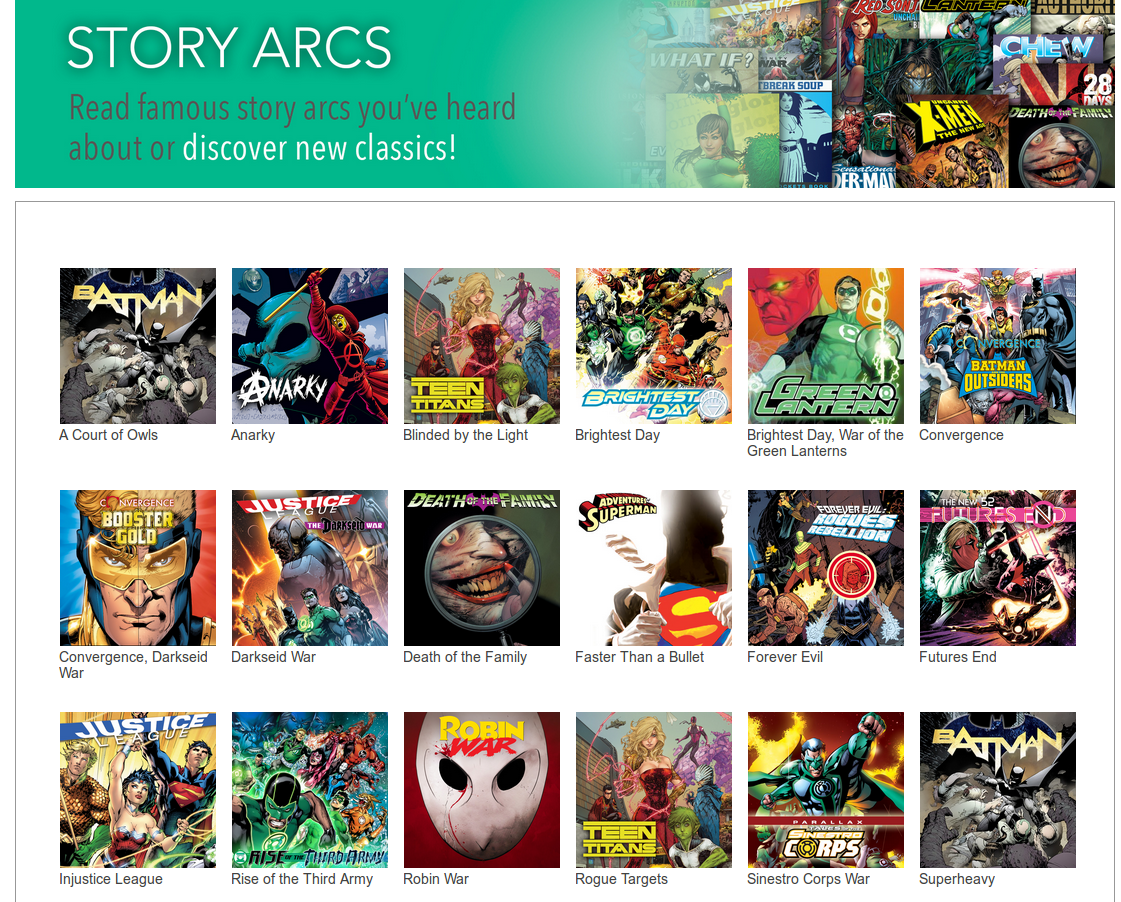
Looks nice is it possible to get the story arcs and comics for a publisher on the first page?
Looks like Mylar can do Story Arc management, but there are some draw backs
- It copies the file to a storac director w/o the publisher structure
> I've confirmed softlinks work with ubooquity so there's no need to duplicate files
> It get the issue # but appends series to the beginning of the file name
> For the folder structure & soflinks I've submitted a feature request
- It doesn't create the cvinfo or folder.jpg ( Not too bad since yah can search manually )
> Submitted a bug report for this item
I wrote a quick script that scans cbz for story arc and then recreate the directory structure under temp ( though that can be changed ) So it goes
Pub -> story arch name -> softlink to comic. The below hack shows how the file structure would look. For a hack it still needs a cvinfo file? I noticed comic tagger will not create one for story arch, it will only let one search up series
You can execute it by going ./arcBuilder.sh -p /<path to your comics>
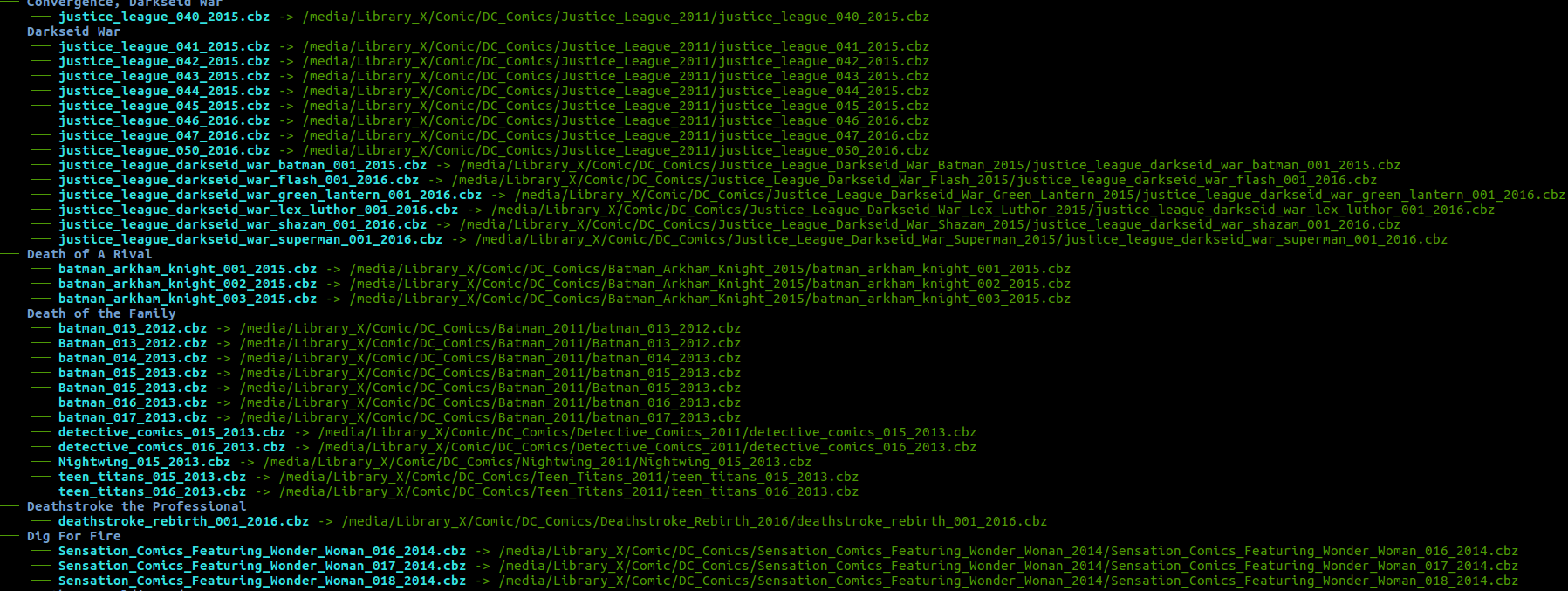
Here's the quick hack let me know what you find on the jquery end
https://www.dropbox.com/s/x8ev10zl0ts107d/arcBuilder.sh?dl=0
Customer support service by UserEcho


Yep yep the new theme was downloaded and comics.css is there with a timestamp of 11:58