Your comments
no more parsing error but still nothing.
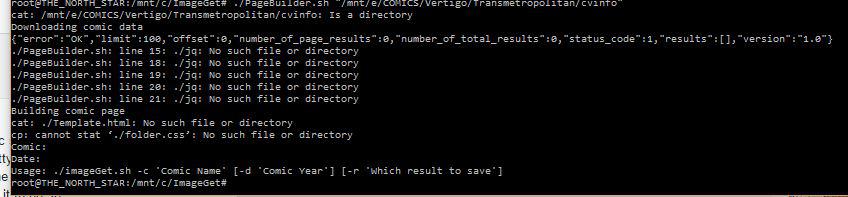
i've downloaded the newest PageBuilder zip and when i try to run it, i still get the same parsing error as above. anyone have any insight as to what may be causing it? my cvinfo file is a simple extension-less file w/ one line that is the url of the series' comicvine page. i've been creating the cvinfo file myself since i dont use (nor know how to use Mylar) nor does the comicrack scraper create it. i've tried w/ a blank cvinfo file and i still get the same parse error. i've added my api key to the sh file as instructed. i really dont know what else i can do. is there a way for me to see what variables/values are being passed into the script that is causing this "invalid numeric literal at line 1, column 10"? i've gotten so desperate that i just started building these html files from scratch using the blank one that gets created and just downloading the cover image and filling in the text info manually...tedious to say the least.
i get those same parsing errors.
surprisingly i can get the standalone getImage.sh command working. it pulled in the proper image file. figures... >_<
yeah after some googling, i figured out the whole cvinfo thing. i cant get the comic scraper to make the file so i did just what you said and cut & paste a url from ComicVine. now im getting parsing errors though.
url is simply: http://comicvine.gamespot.com/street-fighter-unlimited/4050-85643/
and im getting a parse error: Invalid numeric literal at line 1, column 10
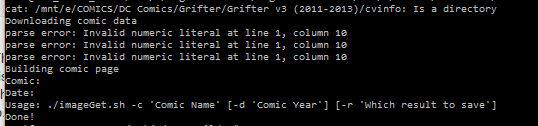
this is a straight up text file (that i remove the extension), one line w/ the copied url. so i dont understand why there is a parsing issue.
EDIT: the parse error actually repeats 3 times
EDIT2: forgot to mention that it IS creating the html and css files but obviously no comic data is being pulled so it's blank.
EDIT3: tried different series' URLs and same parsing error all the time. dont know how to display the command string trying to be parsed so i have no clue what the invalid character is. im assuming it's some sort of JSON error from looking at the PageBuilder script? the thing is, i get the same exact parsing error whether i have a URL on that first line or not which is making me think the URL in the cvinfo file isnt the problem. that said, im at a complete loss...
i guess this is where i get lost because i dont know what a cvinfo file is. is it only generated from using Mylar? as i mentioned, i do all my scraping via comicrack scraper add-on that pulls from comicvine. thanks.
ok so i've activated linux on ubuntu on windows on my Windows 10 OS. im trying to run the commands. i've done the chmod ones but when i try running the PageBuilder.sh i get the message "No cvinfo file found". did i miss a step? im not using Mylar. i have a Comicrack add-on scraping everything for me from Comicvine.
would you mind posting a walkthru for Win10 users? thanks!
uggghhh...i missed the Linux part. my server is on Windows. wasnt there someone on this thread that ran it from MAC OS?
EDIT: do you need Mylar? ive heard of it but never used it. i do have a comicvine api key for the scraper add-on in comicrack.
any chance of a readme for the technically challenged? :)
Customer support service by UserEcho


no dice...still the same parsing errors. the $rawDesc string was the same.
i've actually tried running this w/ NO cvinfo file...and i get those parse errors.
i've tried running this w/ NO cvinfo file OR folder...and i get the same parse errors although w/ this, it tells me the cvinfo folder doesn't exist, yet it still tries to run the script anyway.
EDIT: shot in the dark but does the url in the cvinfo file have to have quotes around it? mine don't.