Your comments
I sent the page to Tom a few hours ago. If he likes it it'll be hosted here soon.
Christian, are you suggesting that someone edit the upstart script with your suggestions or are you reminding us that those things are possible? Do you have the time to add that functionality? I have been researching the creation of a Synology package and it seems straight forward, bit help with the scripting would be nice. Let me know if you have the talent and we can coordinate through google hangouts later.
Tom, this question is answered elsewhere and Tomservo has read the post. Please mark this thread as completed. I will also be creating a simple tutorial within the next few days that you may want to host.
Hi Tomservo! I'm on my phone while my girlfriend drives so I'm sorry for no screenshots. Comicrack defaults to saving the metadata from Comicvine to its local database instead of the comic file. To change this default open the Comicrack options. Find the option for "save metadata to the comic file" and enable it then enable the directly following option titled "automatically write metadata." Now Comicrack will automatically write metadata to the comic after you scrape it, but there are a few caveats: 1) the RAR compression algorithm is copyrighted so comicrack has trouble saving the metadata to CBR files. Fix this by right-clicking a selection of comics and choosing to export the files to CBZ. Wait for the conversion to finish and you will have shiny new open source zip compressed comics! 2) Comicrack sometimes skips automatically updating files. About 10% of the files you scrape will not have their new metadata saved automatically. Solve this by using a smart list that shows only the files that are waiting to be updated. If you can't find the filter when creating your smart list I will attach a screenshot later. Open this smart list to view the files with new metadata that is waiting to be saved to the file. Right-click those books and choose the "update" option with the yellow spiky icon. Your files will be updated! 3) Make sure you are using the most recent version of the scraper plugin from its github page. Comicvine just changed its API access rules and you may get banned if you are using a previous version. 4) Finally, check if the comicinfo.XML file in one of your books was correctly saved by opening the file in 7zip. If you do not see the XML file then Comicrack does not have write permission for your comics directory. I hope this was not too confusing. I might write a quick tutorial on this subject for Ubooquity users since most of us use comicrack and Ubooquity is so much better with scraped comic files. Back to chatting with my passenger ;)
What Justin means is that you should set your directories to whatever directories have the comics right underneath them.
Let's say your directory structure is /volume1/Comics/. You've set your directory to /volume1 so Ubooquity lists the folders that it sees and it sees one named "Comics" which you then have to click through to get to your individual comics series folders.
Let's say you organize your comics by publisher:
- /volume1/Comics/Dark Horse
- /volume1/Comics/DC
- /volume1/Comics/Wild Storm
You wouldn't add /volume1/Comics as your shared folder because right underneath are no comics! There are only more folders used to organize your collection. In this scenario your individual comics folders are under their publisher folder so you'll have to add each of your publisher folders in the admin section.
Here's a visual for you:

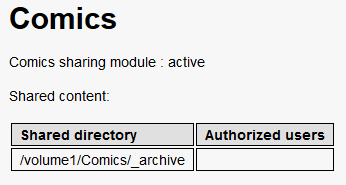
This is my comics organization. DS415 is a network map to /volume1. My comics folders are all stored in _archive which makes the directory I set in Ubooquity: /volume1/Comics/_archive. If I had set the directory to /volume1/Comics I'd see a link after clicking the comics bubble just like you see a link, but mine would be named _archive.
If you are still confused open up your folder structure, take a screenshot, and share it with Justin and I here. We'll tell you what you'll need to add.
The white button brings you to a list of all of your scanned folders. Because the folder where you store your files is named "Comics" this is the word you see when you go in to the comics section. If you go to the admin area and add another folder to scan you'll see that folder there, too.
Elouan, I also use ComicRack to write the ComicInfo.xml file in the cbz archive. Right click on the entry in ComicRack and choose "Clear Data" to remove the xml file. That will do what Ray said and force Ubooquity to sort on the file name, but this is not a good long-term solution. I tried brain storming a solution, but came up empty. I think Tom will have to include an option to parse by filename in a later version.
Elouan's suggestion is correct. Converting to cbz is the best solution, but if Dragon Magazine is an eBook you should use Calibre to convert it to the epub format or use pdfaid (http://www.pdfaid.com/repair-pdf-file.aspx) if you really want to keep the PDF.
Hi Ethan, in case Tom does not include the ability to set file and folder organization soon check out the Library Organizer plugin for ComicRack. You can rename files and folders to almost any pattern you want and it does so automatically.
Customer support service by UserEcho


This would be a great extra feature. If Tom were to externalize the web files and make the Ubooquity variables available through a simple API when building the html files we could make some spectacular graphs.